Kafka, Avro streaming components
Kafka and Avro stream stages.









Click image to open source code in a new tab. Hover over image for stage inputs and outputs
Kafka is the preferred distributed system hub for microservices, CRQS, Event Sourcing and messaging. Most Kafka client coding is generalized and it’s enhanced with backpressure, in-stage error handling, and reliable message processing.
Kafka as a stream source
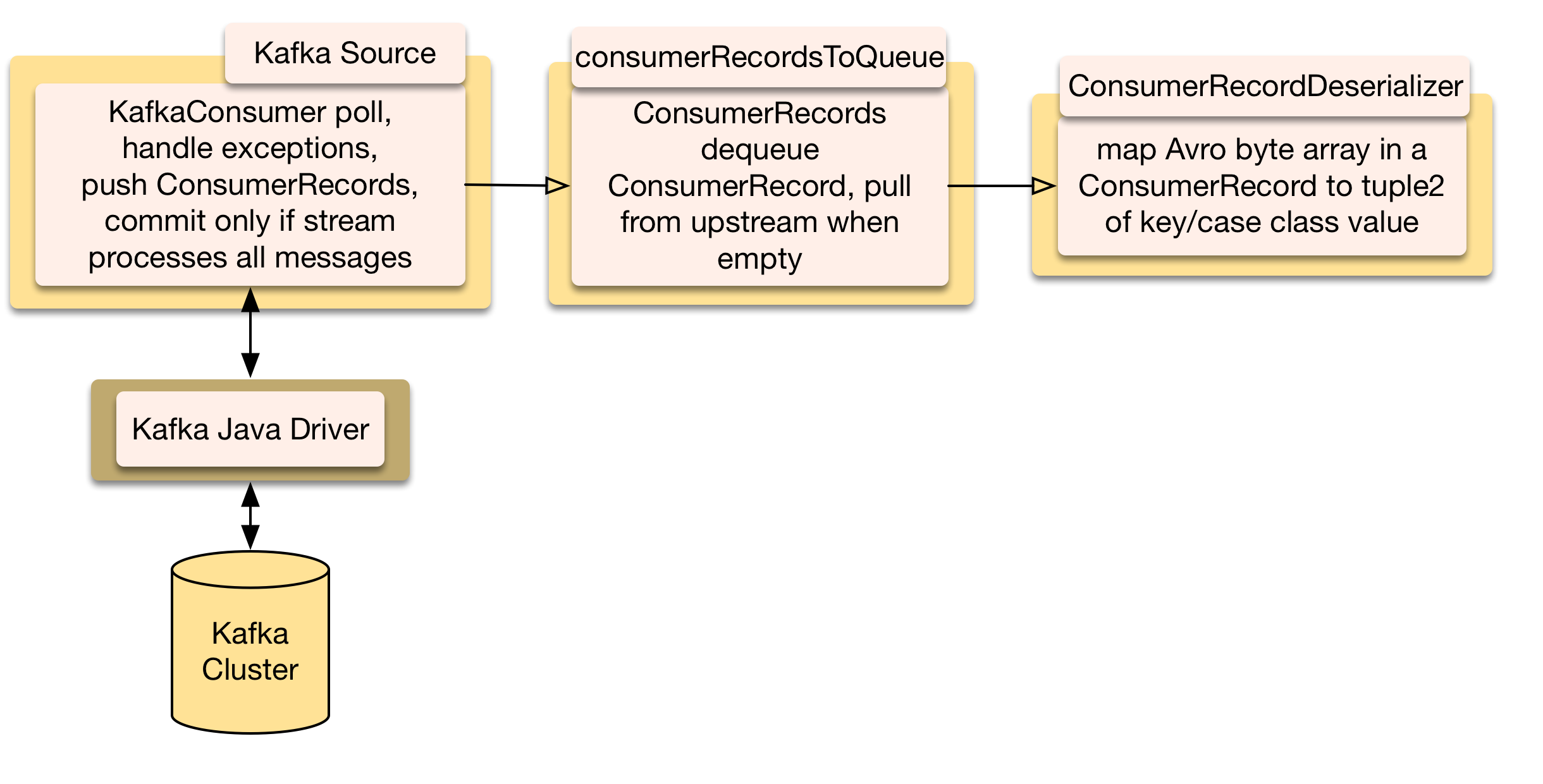
Common stages of streams beginning with a KafkaSource, downstream can be anything
Poll messages from a cluster, queue them, deserialize them, and commit them once processed.
Kafka is written in Scala but its built in driver is written in Java.
KafkaSource wraps the driver and configures a KafkaConsumer which polls and commits messages. These are rare blocking calls in dendrites, so a blocking ExecutionContext is used (Akka Stream’s default ExecutionContext has about as many threads as cpu cores, blocking could cause thread starvation). Available messages are returned in a ConsumerRecords object. If either polling or committing throws a RetriableExceptions it’s retried with exponential backoff delays.
Kafka tracks messages with offsets. Committing a message means its offset is marked as committed. Kafka auto-commits by default but this only assures they were read OK. By turning off auto-commit we wait until they were processed. If any failed, Kafka re-polls those messages.
A key benefit of Akka is Supervision for error handling and recovery, its default behavior is stopping the stream when an exception is thrown. Kafka throws retriable exceptions so KafkaSource has a Decider to handle them. KafkaSource doesn’t commit offsets in a failed stream so records will be polled again. Downstream stages throwing exceptions mustn’t Restart or Resume: a failed message could get through.
ConsumerRecordsToQueue initially queues every ConsumerRecord contained in ConsumerRecords. Then it pushes one for each downstream pull. If the queue is not empty it doesn’t pull from upstream. This is to ensure all messages have been processed. After the queue empties it resumes pulling, causing KafkaSource to commit its previous poll and poll anew.
ConsumerRecordDeserializer maps a ConsumerRecord’s value to a case class and its metadata to a ConsumerRecordMetadata. There’re two flavors of ConsumerRecordDeserializer, one takes a UDF (example with Avro4s) to deserialize from an Array of Bytes to a case class, the other takes an Avro schema and maps to a GenericRecord, which is in turn mapped by a UDF to a case class (example). Either way a deserialized case class and ConsumerRecordMetadata is pushed.
ConsumerRecordMetadata has the message’s topic, partition, offset, timestamp, timestamp type, key, and headers. It can be used to store the key and timestamp in an event log, downstream can fork by partition into parallel streams, timestamps and their type can be updated to show a process state change, offsets can be tracked, and headers can add custom metadata.
Once all polled records pass completely through the stream, ConsumerRecordsToQueue resumes pulling causing KafkaSource to commit the messages and then it polls again.
val dispatcher = ActorAttributes.dispatcher("dendrites.blocking-dispatcher")
def shoppingCartCmdEvtSource(dispatcher: Attributes)(implicit ec: ExecutionContext, logger: LoggingAdapter):
Source[(String, ShoppingCartCmd), NotUsed] = {
val kafkaSource = KafkaSource[String, Array[Byte]](ShoppingCartCmdConsumer).withAttributes(dispatcher)
val consumerRecordQueue = new ConsumerRecordsToQueue[String, Array[Byte]](extractRecords)
val deserializer = new ConsumerRecordDeserializer[String, ShoppingCartCmd](toCaseClass)
kafkaSource.via(consumerRecordQueue).via(deserializer)
}
val runnableGraph = shoppingCartCmdEvtSource(dispatcher)
.via(userFlows) // custom flows here
.to(sink)
Kafka as a stream sink

Common stages of streams ending with a KafkaSink, upstream can be anything
Serialize case classes, send them, and handle errors.
AvroSerializer takes a user’s Avro schema and a serialize function: ccToByteArray can serialize case classes with simple field types. Those with complex fields need a user defined serialize function. Avro4sSerializer is also provided and is often easier to use.
KafkaSink wraps the driver and configures a KafkaProducer and calls its asynchronous send method. It takes care of Java & Scala futures, callbacks and exceptions. Send returns a Guava ListenableFuture with a Kafka Callback. Success invokes an Akka AsyncCallback that pulls from upstream. Failure invokes an AsyncCallback which invokes a Supervision Decider. Stop exceptions stop the stream. Kafka’s RetriableExceptions are retried. If enable.idempotence=true the driver handles retriable exceptions instead of throwing them it also eliminates duplicate sends, if it’s false KafkaSink handles them with exponential backoff delays.
ProducerConfig is a trait for configuring KafkaProducer and creating a ProducerRecord, it has 6 constructors. You extend ProducerConfig with your choice of constructor. Default is topic, key, value leaving Kafka to select the partition and create the timestamp.
val ap = AccountProducer // example custom configured KafkaProducer
val serializer = new AvroSerializer("getAccountBalances.avsc", ccToByteArray)
val sink = KafkaSink[String, Array[Byte]](ap)
val runnableGraph = source.via(serializer).to(sink)
Split Kafka streams by Topic Partition
Kafka TopicPartitions can be processed in parallel, ConsumerRecords can be split into 2 to 22 parallel streams, one per topic partition.
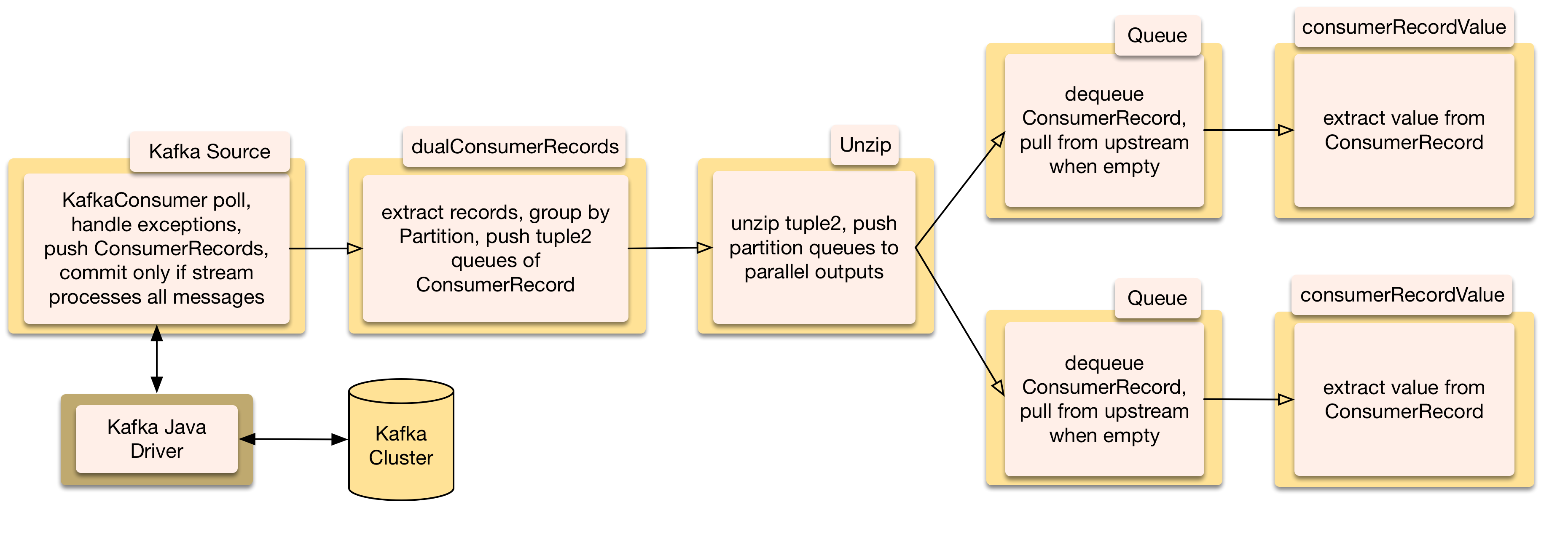
Streams beginning with a KafkaSource that forks parallel downstreams by Kafka partition
dualConsumerRecordsFlow takes a ConsumerRecords for 2 TopicPartitions and enqueues them in 2 queues and pushes them as a Tuple2.
Unzip is a built in Akka Stream stage that splits the tuple into 2 outputs.
The rest of the stages are the same but duplicated in parallel.
tripleConsumerRecordsFlow is provided to extract 3 Topic Partitions.
Example Configurations
Typesafe Config example, and optional, config settings for Kafka are in src/main/resources/reference.conf. You can choose to use Typesafe Config and override these in your application’s src/main/resources/application.conf.
Example consumer configuration in src/main/resources/kafkaConsumer.properties
Example producer configuration in src/main/resources/kafkaProducer.properties
Other Kafka Streaming products
Kafka Streams has a new Transactions API said to guarantee exactly once processing, dendrites is at least once but you can eliminate duplicates on the Producer side setting enable.idempotence=true and compensate for duplicates, or filter them, on the consumer side.
Reactive Kafka also has a Source and Sink for Akka Streams.