dendrites
Cut down learning curves and custom coding putting together these new generation technologies. Streaming components served together and à la carte, composable to Microservices, CRQS, Event Sourcing, Event Logging and message-driven systems. They’re container neutral, deployable to anything that runs on a JVM: Docker, Mesophere, Scala or Java applications etc.
Software should be easy to modify throughout its lifecycle, be resilient in production, and make the most of multi-core CPUs.
Scala’s functional and concurrent programming features are made for multi-core CPUs and writing concise, modifiable code.
Akka Streams are Reactive. They use backpressure so fast producers don’t overflow slow consumers. Stream stages are a nice new form of encapsulation. They’re pluggable, debuggable and testable. Underneath they’re Actors but it’s a nicer programming model: write functions, unit test, pass them to stages, plug stages into streams, then integration test.They also have Supervision to handle and recover from exceptions.
Stream stages may need additional objects, values, or functions that don’t change while the stream is running. Scala’s currying and partially applied functions and implicit parameters let generic stages, like map, which expect just one input, work with functions having several parameters.
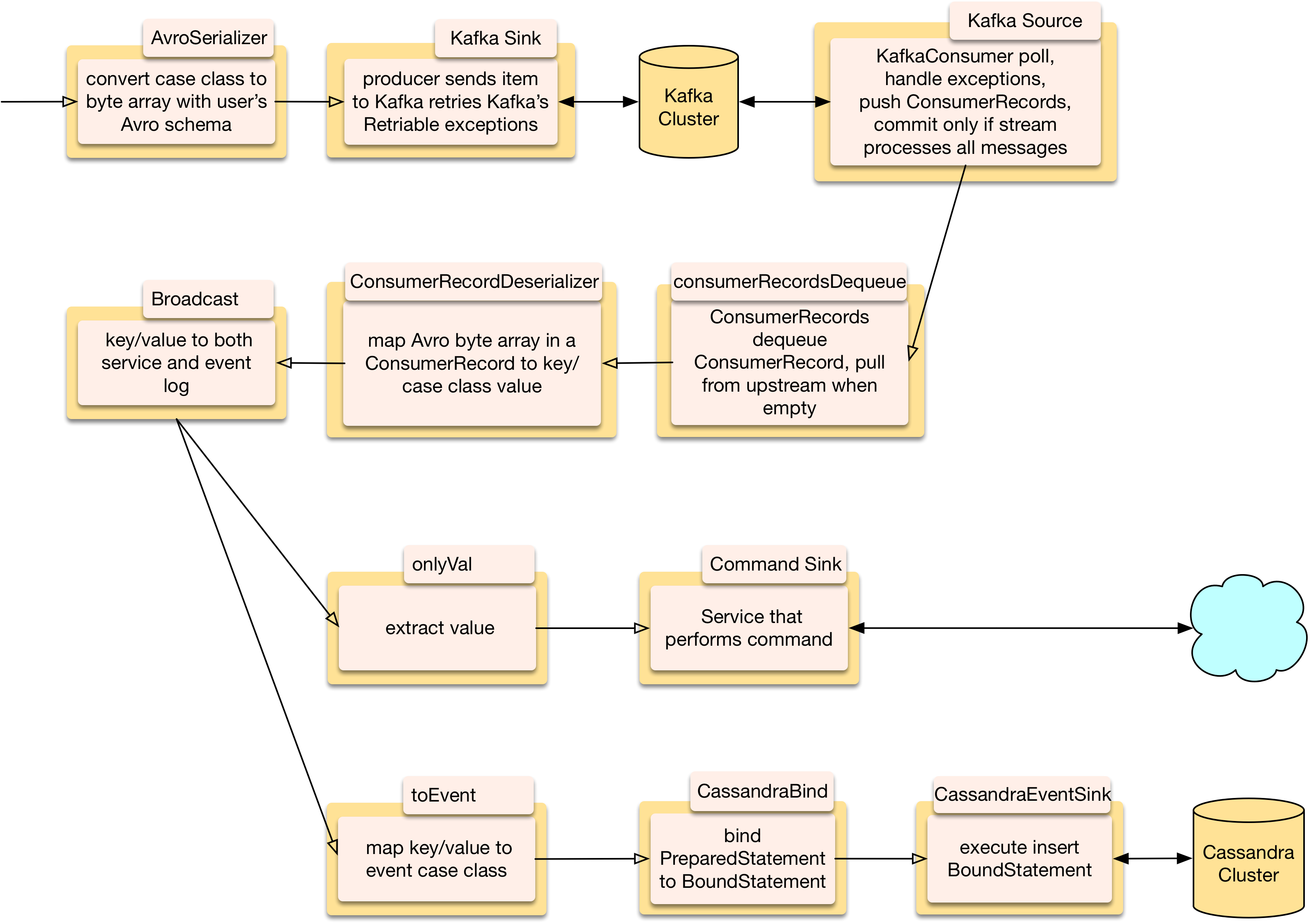
Custom stages are necessary when functions need post-processing. A pure function’s result is simply pushed downstream but stream stages are also good for calling drivers, services, and things that may return errors or throw exceptions. In-stage result handling has access to the input and other context information. Temporary errors, like dropped connections, are retried with exponential backoff. Non-fatal errors are mapped to Akka Supervision. Logging is vital to knowing what happens in asynchronous code, log messages are more useful when they have context information. Kafka polling and Cassandra queries return many elements, queuing stages output a specified number of them when pulled from downstream. Kafka polling repurposes backpressure to commit messages after they’ve been processed. When upstream is complete the next stage gets a shutdown message, longer running stages need a lifecycle guard to keep the stage alive while an operation is in progress.
Generic fan-out and fan-in stages make for an elegant way to call parallel services and proceed when results are ready.
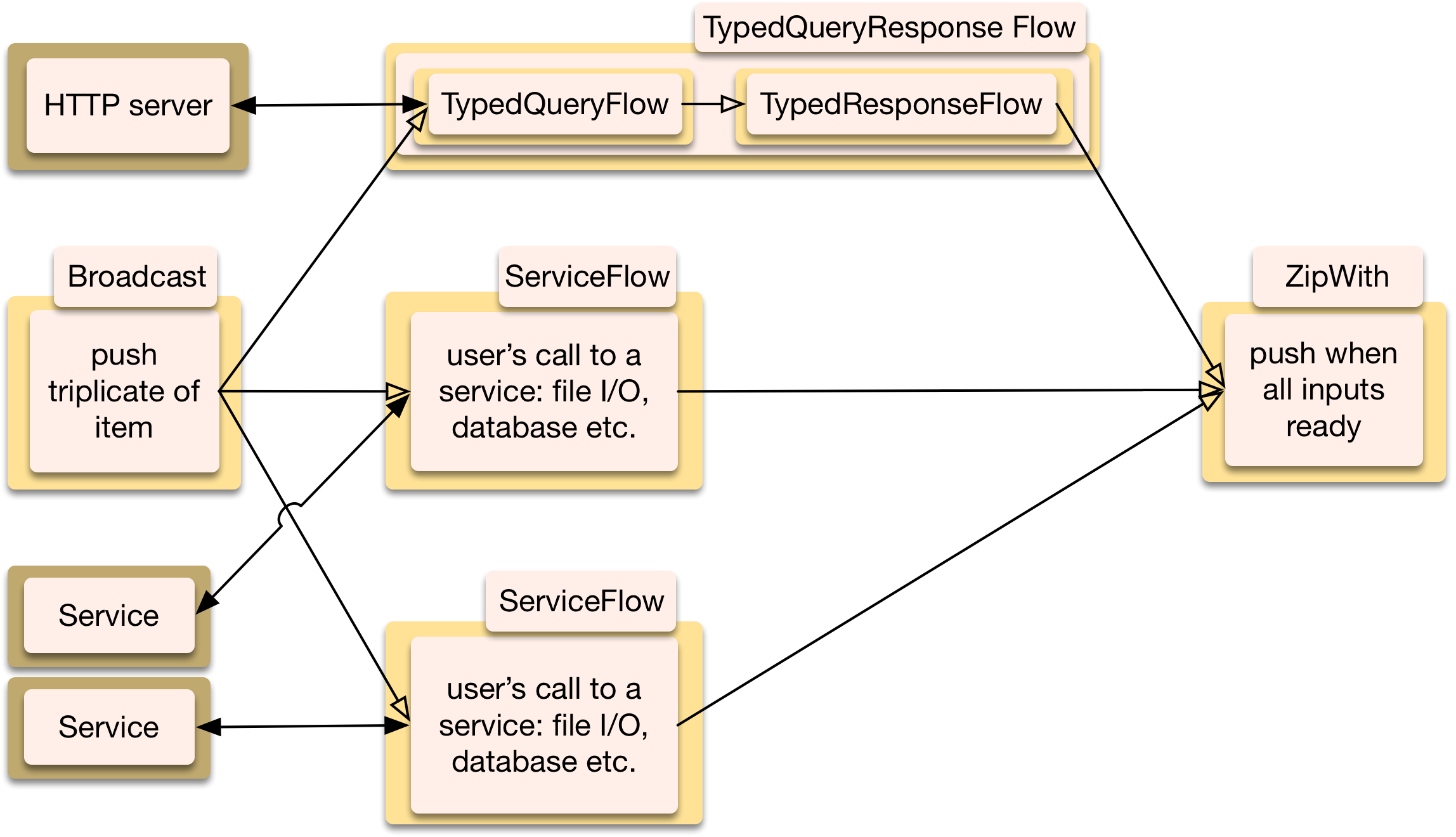
Stream segment with 1 input calling services in parallel and 1 aggregated output
A Runnable stream can be passed around as an object.
Programing teams short of experienced Scala developers can be productive and confident. Those new to Scala can start with stand-alone functions then climb a skill ladder, learning progressively instead of being overwhelmed by too many new concepts up front as they would be coding monolithic applications.
Stream stages are simple to modify: most are just a few lines of code and changing one doesn’t trigger a cascade of other changes. They can be opinionated, and YAGNI, they don’t have to bloat in anticipation of what users might want. Pre-built stages can be used as templates for new ones.
Stages are looser than loosely coupled, adjoining ones must only agree on input/output type. This frees developers to quickly swap and modify.
Kafka is a fast durable hub between systems and doesn’t overflow when downstream systems go down. Wrapping a Source and a Sink around Kafka’s built-in Java Driver integrates it with Akka Streams. Backpressure is repurposed to ensure a stream successfully processed Kafka messages.
Cassandra is a popular highly scalable databases: it’s peer to peer with no single point of failure, it elastically adds or removes nodes without restarting, it replicates data to tolerate faults. dendrites wraps DataStax Java Driver. Stand-alone functions configure and create a cluster, session, keyspaces, tables, and pre-parse PreparedStatments. Flows bind stream data to PreparedStatements to query, and to use Cassandra’s Lightweight Transactions to update. Sinks insert, delete, and handle user defined compound statements.
Distributed databases like Cassandra aren’t suited to the traditional Request/Response model, like Oracle is: writes are fast but queries over many nodes are slow. CRQS, Event Sourcing and generally separating writes from reads are the preferred way to use distributed databases and streaming fits these models.
Akka HTTP client API is wrapped in stand-alone non-blocking request and response handlers and Flow stages: streams can include HTTP clients. Its server side has a beautiful high level domain specific language which is easy to write and understandable by non-programmers.
Spray is now part of Akka HTTP and can marshal case classes to JSON requests and unmarshal responses to case classes with a few lines of code.
Twitter’s Algebird has featherweight hashing components that provide approximate statistics on streaming data in near real time.
Typesafe Config example, and optional, config settings for logging, Kafka, Cassandra, HTTP, Algebird, threads, and timers are in src/main/resources/reference.conf. You can choose to use Typesafe Config and override these in your application’s src/main/resources/application.conf See Akka config user guide.
Logback example config settings are in /src/test/resources/logback.xml. Your application configuration is done separately. You can copy logback.xml to your /src/main/resources/ and modify it.